[SYNAPSE] 여러분은 무슨 목적으로 기록하시나요? 어쩌면 그 기록은 이미 죽었을지도 모릅니다.
[SYNAPSE] 여러분은 무슨 목적으로 기록하시나요? 어쩌면 그 기록은 이미 죽었을지도 모릅니다.
💀 지금까지의 기록은 죽었다.기존 기록의 의미와 가치저는 노션을 7년 동안 사용했습니다.매일 새로운 노트를 생성했고 새로운 기록을 남겼습니다.저한테 기록은 작성하는 것만으로 오늘도
blog.juyear.dev
이전 글 읽으러 가기!
👋 소개 및 회고
안녕하세요. 대학생 개발자 주이어입니다.
오늘은 저번에 소개드렸던 SYNAPSE 프로젝트의 개발 일지 중 첫 번째 글 입니다.
오늘은 대략 아래와 같은 내용을 적어보려 합니다.
- GraphRAG의 아키텍처 설계와 기존 구조의 문제점
- 메인 서버와 AI 서버를 왜 분리했는가
- DB 접근 권한을 위해 어떤 아키텍처를 고민했는가
이 세 가지를 중심으로 작성하며 필요한 내용은 추가해서 작성할 예정입니다.
⚙️ GraphRAG의 아키텍처 설계
GraphRAG의 작동 과정
GraphRAG의 아키텍처를 설계하기 위해서는 GraphRAG의 작동 과정을 먼저 이해해야 합니다.
기능의 작동 과정을 알아야 그에 맞는 아키텍처를 설계할 수 있기 때문입니다.

우선 SYNAPSE에서는 위와 같은 과정으로 GraphRAG가 작동합니다.
단계별로 간단히 정리하자면 아래와 같습니다.
- Note Input : 사용자가 새 노트를 작성합니다.
- Embedding : 새 노트를 Embedding 합니다.
- Save Embedding : 생성된 Embedding을 DB에 저장합니다.
- Vector Search : 새 노트를 기반으로 유사한 노트를 검색합니다.
- Generate Link Reason : 검색된 유사한 노트와 새 노트의 연결 이유를 생성합니다.
- Save Link : 연결 이유를 DB에 저장합니다.
- Graph RAG : 최종적으로 Graph를 구축하여 Graph RAG가 작동할 수 있도록 설계합니다.
초기 아키텍처 설계와 문제점
이러한 GraphRAG를 구현하기 위해서 처음에는 단순하게 Note 도메인에서 전체를 구현하려 했습니다.
'결국 note를 embedding하고, note를 검색하고, note를 연결하니 note 도메인이겠구나'
라고 생각하고 아키텍처를 설계하였습니다.
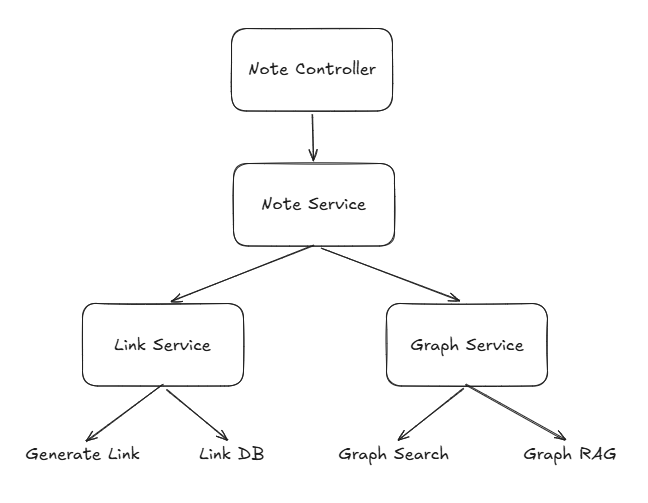
하지만 아키텍처를 구체적으로 설계하는 과정에서 해당 아키텍처는 NoteService가 담당하는 책임이 너무 많아지고, Link 도메인과 Graph 도메인의 구현까지 알아야 한다는 문제점이 있었습니다.
이게 문제가 되는 이유는 아래와 같습니다.
[구조적인 문제]
- NoteService가 Link와 Graph 도메인의 구현까지 알고 있다.
- 새로운 도메인이 추가될수록 NoteService의 의존성과 책임이 계속 증가한다.
- 하나의 Service가 여러 도메인의 비즈니스 흐름을 담당하게 된다.
[유지보수 문제]
- Link DB 변경 -> NoteService 수정 필요
- Graph 로직 변경 -> NoteService 수정 필요
- 기능이 늘어날수록 NoteService의 수정 범위가 커진다.
이러한 문제가 있지만, GraphRAG를 구현하기 위해서는 다양한 도메인의 Service가 필요할 수 밖에 없었고,
이를 해결하기 위해 Orchestrator 구조를 도입하였습니다.
Orchestrator를 적용한 아키텍처
Orchestrator는 다양한 도메인의 Service를 조합해 하나의 비즈니스 흐름을 설계하는 역할을 담당합니다.
즉, 하나의 Service가 다른 도메인의 Service를 알아야 한다는 문제점을 해결하면서도, 다양한 Service를 활용한 GraphRAG 구현을 할 수 있게 됩니다.
기존에는 NoteService가 LinkService를 의존성 주입(DI)받아 사용해야 했다면,
이제는 Orchestrator에서 NoteService와 LinkService를 각각 가져와 조합해서 사용할 수 있습니다.
이러한 구조는 각각의 Service가 자신만의 책임을 담당할 수 있도록 도와주고,
실제 흐름은 Orchestrator가 담당한다는 책임 분리의 장점이 있습니다.
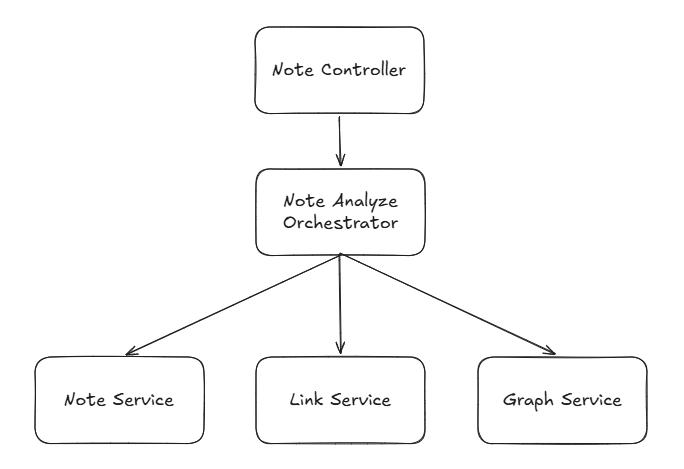
그림으로 보면 구조가 더 명확해집니다.
NoteService가 부모 Service처럼 존재하던 기존 아키텍처와 달리 모든 Service가 동일한 선상에 있으며, 서로의 비즈니스 로직을 전혀 몰라도 됩니다.
Orchestrator에서 Service들을 조합해 GraphRAG를 구현하기 때문입니다.
💡추가로 고민했던 것들
- FastAPI 설계 철학에는 어떤 아키텍처가 적합한가?
- Service에서 직접 AI를 호출할 것인가?
- AI 기능을 service로 둘 것인가, util로 둘 것인가?
🗂️ 메인 서버와 AI 서버를 왜 분리했는가
현재 서버 구조

현재 SYNAPSE는 위와 같이 메인 서버와 AI 서버를 분리하여 개발하고 있습니다.
메인 서버는 전반적인 비즈니스 로직과 도메인을 담당하고,
AI 서버는 Embedding 생성, LLM 호출 등 AI와 관련된 기능을 담당합니다.
이렇게 서버를 분리한 이유는 크게 두 가지가 있었습니다.
사용자 경험 (UX)

아까전에 보여드렸던 GraphRAG 과정을 다시 보면 굉장히 복잡하고 로직이 긴 것을 알 수 있습니다.
또한 Embedding 생성, LLM 호출과 같은 오래 걸리는 AI 작업을 수행하는 것을 확인할 수 있습니다.
이러한 경우 AI 작업을 분리하지 않으면, 사용자가 노트 저장을 누르고 값이 반환될 때 까지 몇 초에서 수십초까지 기다려야할 수도 있습니다.
사용자는 노트를 저장했을 뿐인데, 지금 당장 필요하지도 않은 AI 작업을 위해 기다리게 되는 것이고 나아가 사용자는 '렉이 걸린다' 와 같이 오해하는 문제가 생길 수도 있습니다.
이러한 문제를 해결하기 위해 일반적으로 처리가 오래 걸리는 AI 기능을 분리해야 겠다고 생각했습니다.
서버 안정성과 성능
사용자 UX를 위해서 분리하는 것은 알겠지만 그렇다고 꼭 서버를 분리해야 하는 것은 아닙니다.
다양한 비동기 처리 방법을 활용해 서버를 분리하지 않고도 충분히 해결할 수 있습니다.
그럼에도 불구하고 서버를 분리한 이유는 '리소스 격리' 때문이었습니다.
AI 기능은 일반적인 CRUD API와 달리 CPU와 메모리를 많이 사용하며 처리 시간도 상대적으로 긴 경우가 많습니다.
이러한 AI 기능을 메인 서버와 함께 처리하면 여러가지 문제가 발생할 수 있다고 판단했습니다.
AI 기능을 처리하기 위해 CPU와 메모리를 많이 사용하면서 메인 서버의 전반적인 성능이 저하될 수 있기 때문입니다.
예를 들어 AI 기능을 처리하는 동안 카테고리 설정, 노트 삭제와 같은 기본적인 API 성능에도 문제가 생기는 것입니다.
또한 AI 기능처럼 외부 LLM API에 크게 의존하며, 네트워크 지연이나 장애의 영향을 직접 받을 수 있는 서비스를 메인 서버와 같이 두는 것은 문제가 될 수 있다고 생각했습니다.
AI 기능에서 발생한 장애가 메인 서버까지 전파되어 전체 서비스에 영향을 줄 가능성이 있기 때문입니다.
따라서 서버 안정성을 높이고, 장애의 영향 범위를 최소화하기 위해 AI 서버를 분리하게 되었습니다.
🤔 DB 접근 권한을 위해 어떤 아키텍처를 고민했는가
AI 서버는 권한을 어디까지 가져가야 하는가
GraphRAG를 위한 아키텍처도 설계했고, AI 서버도 분리했으니 이제 구현만 진행하면 된다고 생각했습니다.
하지만 실제로 구현을 진행하다 보니 문제가 하나 발생했습니다.
바로 AI 서버에서의 DB 접근 문제였습니다.
이 그림을 다시 확인해보면 Save Embedding, Vector Search, Save Link와 같이 DB를 필요로 하는 작업들이 있는 것을 알 수 있습니다.
하지만 AI 서버에는 DB가 연결되어 있지 않았습니다.
그럼 'AI서버에 DB를 연결하면 되는거 아니야?' 가 가장 먼저 떠오릅니다.
하지만 이 방법은 아키텍처 관점에서 고민이 필요한 선택이었습니다.
그 이유는 AI 서버 설계 원칙에 있었습니다.
AI 서버는 이름 그대로 AI 기능을 수행해주는 보조 서버일 뿐 직접적으로 비즈니스 규칙을 구현하거나 DB를 수정하는 등의 도메인 관리의 주체가 되어서는 안 된다고 생각했습니다.
'그래도 필요하면 연결해야지...', 하지만 단순히 설계 원칙을 위해서 연결하지 않겠다고 생각한건 아니었습니다.
대표적인 이유 중 하나는 DB를 두 개의 서버에서 관리하는 것이 적절하지 않다고 판단했습니다.
왜냐하면 DB를 두 개의 서버에서 관리할 경우 하나의 도메인에 대한 소유권이 두 개로 나누어지는 것이라고 생각했습니다.
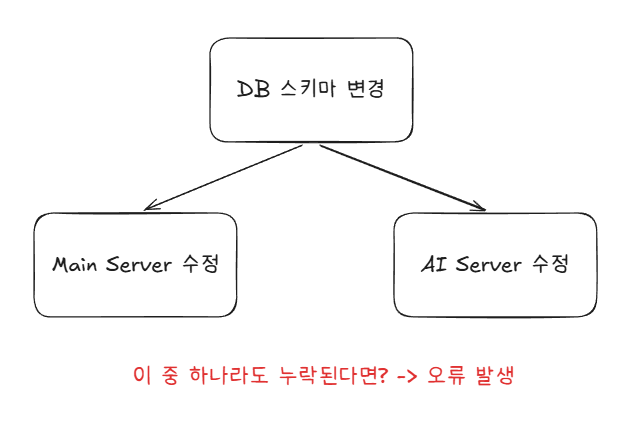
예를 들어 위 그림처럼 테이블의 구조를 수정할 경우 이에 맞게 메인 서버와 AI 서버를 모두 수정을 해줘야 합니다.
해당 도메인에 대한 소유권을 두 개의 서버가 모두 가지고 있기 때문입니다.
이러한 설계는 별로 좋지 않은 설계라고 판단했습니다.
이쯤되면 '도메인에 따라 소유권을 분리하면 되지 않나?' 라는 생각이 듭니다.
하지만 이미 메인 서버에서 담당하고 있는 도메인(Note)이기 때문에 적절한 방법은 아니라고 생각했습니다.
이러한 문제를 해결하기 위해 여러가지 아키텍처를 고민하게 되었습니다.
어떤 아키텍처를 고민했고 왜 선택했는가
저는 이러한 소유권 문제를 해결하기 위해 5가지 아키텍처를 생각하였습니다.
지금부터 각 아키텍처에 대해서 설명하고 왜 선택하지 않았는지, 왜 선택했는지 설명드리려고 합니다.
[1. AI 서버에도 DB를 연결하자.]
해당 아키텍처에 대해서는 위에서 말씀드렸기 때문에 넘어가도록 하겠습니다.
[2. Orchestrator를 메인 서버에서 수행하고, AI 서버는 핵심 기능만 담당하자.]
해당 아키텍처는 'AI 서버가 Orchestrator를 수행하기 때문에 이런 문제가 생기는거 아닌가?' 라는 생각에서 나온 아키텍처 입니다.
AI 서버가 단순히 AI 기능을 처리하는 서버라고 하기엔 Orchestrator와 같은 계층을 사용할 정도로 너무 깊게 관여하는 것은 아닐까 생각했습니다.
그래서 저는 메인 서버가 Orchestrator를 수행하면서 진짜로 AI가 사용되는 부분에서만 AI 서버에 요청하는 방식을 생각해보았습니다.

하지만 해당 아키텍처는 AI 서버를 자주 호출하며 지속적인 API 왕복이 발생한다는 문제가 있었고, 결과적으로 반환 지연 문제로 나타날 수 있었습니다.
사용자 경험을 위해 비동기로 Orchestrator를 실행한다는 관점과 맞지 않다고 생각했습니다.
[3. AI서버에서 필요한 데이터를 API로 요청하자.]
이는 사실 두 번째 아키텍처와 비슷하지만 다른 문제점을 발견하여 설명하려고 합니다.
AI 서버에서 Orchestrator를 수행하며 메인 서버에 필요한 데이터를 요청하는 것은 똑같이 지연 문제가 발생합니다.
하지만 해당 아키텍처를 선택하지 않은 가장 큰 이유는 '역방향 의존성' 때문입니다.
메인 서버가 AI 서버를 호출하는 것이 아닌 역으로 AI 서버에서 메인 서버를 호출하며 의존하게 됩니다.

또한 '메인 서버 -> AI 서버 -> 메인 서버'와 같이 '순환 호출 구조' 문제도 발생하게 됩니다.
따라서 해당 아키텍처는 선택하지 않았습니다.
[4. 필요한 데이터를 미리 넘겨주자.]
해당 아키텍처는 처음에 순간 '이렇게 하면 되겠네' 라고 생각했습니다.
메인 서버에서 AI 서버를 호출할 때 미리 필요한 데이터를 넘겨주면, AI서버는 앞서 말한 문제들이 발생하지 않고 Orchestrator를 잘 수행할 수 있었습니다.
하지만 조금 더 고민해보니 적합하지 않은 아키텍처라고 생각하게 되었습니다.
가장 큰 이유는 embedding 데이터의 크기 때문이었습니다.
embedding 데이터는 노트 길이에 따라 얼마든지 커질 수 있고, Chunking을 적용하면 하나의 노트가 여러 embedding 데이터로 분리되며 더더욱 커질 수 있었습니다.
이러한 데이터를 매번 API 요청에 포함하여 전달하는 것은 통신 비용이 증가하고, 요청 자체도 불필요하게 무거워질 수 있다고 생각했습니다.
또한 AI 서버가 필요로 하는 데이터가 늘어날수록 API 요청의 형태도 함께 변경되어야 한다는 문제가 있었습니다.
{
"noteId": 1
}예를 들어 초기에는 noteId만 필요했지만
{
"noteId": ...,
"embedding": ...,
"links": ...,
"graph": ...
}이후에 기능이 추가되며 다양한 데이터가 필요하다면 위와 같이 API 요청의 크기가 계속해서 커지게 됩니다.
이는 결국 메인 서버와 AI 서버가 서로 어떤 데이터를 주고받아야 하는지 강하게 의존하게 되고, 장기적으로 유지보수에도 불리한 구조라고 판단했습니다.
[5. AI 서버에 Read Only DB를 연결하자.]
해당 아키텍처가 SYNAPSE에 최종적으로 선발된 아키텍처입니다.
처음에는 AI 서버에 DB를 연결하는 것 자체를 고려하지 못했습니다. AI 서버는 AI 기능만 수행하는 보조 서버라고 생각했고, 메인 서버가 관리하는 DB에 직접 접근하는 것은 적절하지 않다고 판단했기 때문입니다.
하지만 여러 구조를 비교하면서 문제의 본질은 DB 연결 자체가 아니라 도메인의 소유권이라는 것을 깨달았습니다.
AI 서버가 메인 서버의 도메인을 직접 수정하거나 관리하지 않고, 필요한 데이터를 조회(Read)하는 역할만 수행한다면 기존에 우려했던 소유권 문제도 발생하지 않았습니다.
그래서 AI 서버 전용 Read Only 권한을 생성하여 필요한 데이터만 조회하도록 구성했고, 이를 통해 도메인의 책임은 유지하면서도 GraphRAG 구현에 필요한 데이터를 효율적으로 활용할 수 있었습니다.
그럼에도 불구하고 아직 해결되지 않은 문제가 하나 있습니다.
바로 데이터 저장입니다.
읽기 권한만 있는 AI 서버가 embedding 데이터와 link 데이터를 저장하기 위해서는 메인 서버를 호출해야 합니다.
그럼 3번째 아키텍처에서 설명드렸던 '역방향 의존성' 문제가 발생하게 됩니다.
이 문제에 대한 해결 방법은 다음 글에서 정리할 예정입니다.
(스포 - Redis를 활용한 서버 의존도 낮추기)
최종적인 현재 아키텍처
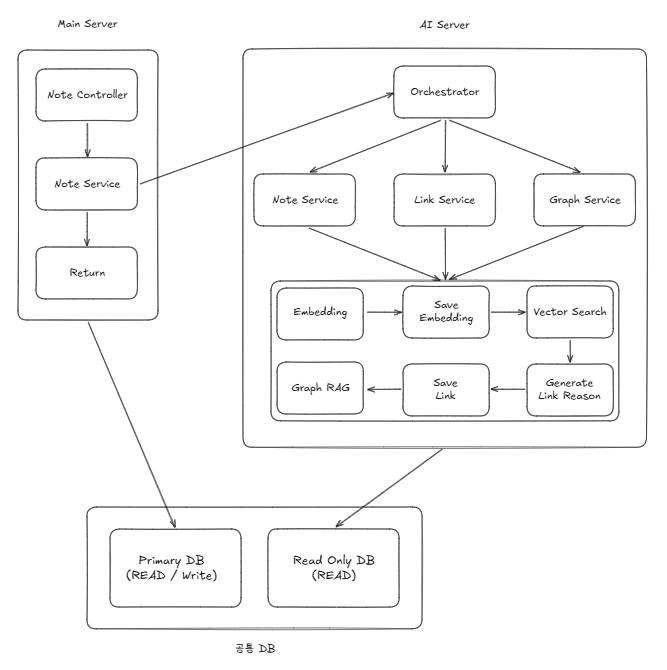
오늘 다룬 내용을 토대로 최종 아키텍처 그림을 그려보았습니다.
제가 잘 그린거지 모르겠지만... 오늘 다룬 내용은 다 들어가 있는 것 같습니다.
😊 마무리
✅ GraphRAG 아키텍처 설계
✅ Orchestrator 도입
✅ 메인 서버 AI 서버 분리
✅ DB 접근 권한 및 도메인 소유권 문제 해결
❌ AI 서버에서의 데이터 저장
❌ Redis 도입
❌ 비동기 처리 (아직 비동기를 구현하진 않음)
[진행 상황 정리]
이번 글에서는 GraphRAG를 구현하기보다 GraphRAG를 구현하기 위한 기반 아키텍처를 설계하는 과정을 정리했습니다.
다음 글에서는 이번 글에서 남겨둔 마지막 문제인 AI 서버의 데이터 저장과 Redis Streams를 이용한 비동기 이벤트 처리를 다뤄보려고 합니다.
지금까지 읽어주셔서 감사드리며, 다음에 더 좋은 글로 돌아오도록 하겠습니다.
by. 대학생 개발자 주이어
KYT CODING COMMUNITY Discord 서버에 가입하세요!
Discord에서 KYT CODING COMMUNITY 커뮤니티를 확인하세요. 25명과 어울리며 무료 음성 및 텍스트 채팅을 즐기세요.
discord.com
KYT CODING COMMUNITY 가입하기!
'[Main Projects] > [SYNAPSE]' 카테고리의 다른 글
| [SYNAPSE] 여러분은 무슨 목적으로 기록하시나요? 어쩌면 그 기록은 이미 죽었을지도 모릅니다. (2) | 2026.06.24 |
|---|
