[SANGMYUNG AI] 사용자 경험을 위한 RAG 답변 생성 최적화 개발 (병렬 처리, k값 수정 등)
[AI CHAT BOT] 응답 속도 개선을 위한 스트리밍 설계, Next -> Nest -> Python 실시간 렌더링
[AI CHAT BOT] 응답 속도 개선을 위한 스트리밍 설계, Next -> Nest -> Python 실시간 렌더링
[Python] 멀티프로세싱으로 처리 속도 올리기 (multiprocessing)이전 글 읽으러 가기! 👋 소개안녕하세요! 대학생 개발자 주이어입니다! 저는 현재 진행 중인 프로젝트에서 단순히 GPT API를 호출해 답변
blog.juyear.dev
이전 글 읽으러 가기!
👋 소개
안녕하세요! 대학생 개발자 주이어입니다!
오늘은 제가 RAG 답변 생성 시간을 최적화하기 위해 시도했던 여러 작업들과 그 효과, 그리고 실제 개선 결과를 정리해보려고 합니다. FAISS 인덱스 구조 변경, k값 조정 등 다양한 방법을 적용해봤고, 직접 측정한 생성 시간과 함께 확실한 분석이 가능하니, 저와 비슷한 고민을 하고 계셨던 분들께 도움이 되길 바랍니다!
⏱️ 기존 속도 & 측정 방식
기존 속도
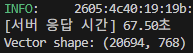

위 사진은 기존 답변 생성 시간을 측정한 사진입니다.
67.5초는 자주 측정되는 시간대는 아니었지만, 이렇게 오래걸릴 때도 있다는 것을 알려드리기 위해 첨부했습니다.
평균적으로는 38초정도가 걸렸고, 이는 사용자 경험에 굉장히 큰 악영향을 미칠 것이라고 생각했습니다.
저 또한 사용자였다면 한 두번 써보고, 오래 걸려 안쓰게 될 것 같다는 생각이 강하게 들었습니다.
측정 방식
async def message(data:MessageRequest):
start_time = time.time()
# 서버 처리
end_time = time.time()
duration = end_time - start_time
print(f"[서버 응답 시간] {duration:.2f}초", file=sys.stderr, flush=True)답변 생성 시간은 답변이 완료된 시간에서, python 서버에서 API 요청을 받은 시간을 빼는 방식으로 측정했습니다.
(오로지 python에서 답변을 생성하는 시간만을 측정하기 위해)
🗂️ FAISS 인덱스 구조 변경
제가 가정 먼저 시도했던 방법은 FAISS 인덱스 구조를 변경하는 것이 였습니다.
저는 기존에 IndexFlatL2라는 완전 탐색 기반의 인덱싱 방식을 사용하고 있었습니다.
IndexFlatL2는 100%의 정확도라는 큰 장점을 가지고 있었지만, 느린 탐색 속도, 많은 메모리 사용량 등의 문제가 있었습니다.
심지어 저는 railway의 무료 버전의 서버를 이용하고 있었기 때문에 이 부분이 큰 문제가 될 수 있겠다고 생각했습니다.
index = faiss.IndexHNSWFlat(768)그래서 저는 중요도가 높지 않은 데이터에 대해서는 IndexHNSWFlat 인덱싱 방식을 적용하고자 했습니다.
IndexHNSWFlat 방식은 그래프 기반 근사 검색 알고리즘을 사용하는 방식이고,
근사 검색이기에 정확도가 약간 떨어지는 대신 메모리 사용량이 적고, 빠른 검색이 가능하다는 장점이 있었습니다.
그래서 저는 바로 적용을 한 후 측정을 해봤습니다.
하지만 예상과는 다르게 실제 생성 시간은 오히려 더 오래 걸리거나, 비슷한 수준이었습니다.
이에 대해서 찾아보니, 데이터 수가 충분히 많지 않을 경우 오히려 느릴 수도 있다는 사실을 알게되었습니다.
그 이유는 HNSW의 그래프 구축 때문이었습니다.
HNSW는 그래프 기반 근사 탐색인 만큼, 초기에 그래프를 구축해야 하는데, 데이터가 적을 경우 이 시간이 오히려 IndexFlatL2의 검색 시간보다 오래걸릴 수 있다는 점이 문제였습니다. 여러 측정 결과에서 데이터가 약 10만개 이상일 경우에 HNSW가 효능을 발휘할 수 있다고 하였습니다.
저는 현재 데이터가 약 3만개 정도였고, 그렇기에 이 방법은 답변 생성에 큰 영향을 주지 못하였습니다.
💡 요약
- Flat -> HNSW 변경은 데이터 양이 많을 경우에 효과적
- 소규모 데이터에서는 오히려 느릴 수 있음
- 생성 시간에 큰 변화가 없어 기존 Flat으로 유지함
⚙️ k값 조정
두 번째로 시도했던 방법은 가장 간단하면서도 효과적인 k값 조정이었습니다.
여기서 k값이란, FAISS를 통해 유사한 문서를 찾을 때 상위 몇개의 문서를 가져올지를 정해주는 값입니다.
예를 들어 k값이 5라면, 수많은 데이터 중에 질문과 가장 유사한 문서 5개만 가져오게 되는 것이죠.
저는 공지 데이터와 커뮤니티 데이터에 모두 k값 7을 적용하고 있었습니다.
k값 7은 그렇게 큰 값은 아니지만, 제 프로젝트의 경우 Reranker를 사용해서 k값의 5배 많은 문서를 가져와 작업을 하고 있었기에 이 값을 수정하기로 했습니다.
공지 데이터의 경우 중요도가 높은 문서들이기 때문에 k값 7을 유지했지만, 커뮤니티 데이터에는 k값을 조정해도 괜찮을 것 같다는 생각이 들었습니다.

결론적으로 커뮤니티 데이터의 k값을 7에서 4로 변경을 했고, 답변 생성 시간이 평균 약 30초 정도로 8초 가량의 시간을 개선할 수 있었습니다.
k값을 낮출 경우, 답변 품질이 낮아지는 문제가 발생할 수 있지만,
이후 여러 테스트를 거치면서 답변 생성 품질에는 큰 영향이 없다고 판단하였습니다.
💡 요약
- 커뮤니티 데이터의 k값을 7에서 4로 조정함
- 약 8초 가량의 시간을 줄일 수 있었음
- 답변 품질에도 영향이 없다고 판단
⚡ 병렬 처리
제가 마지막으로 시도했던 방법이자, 사용했던 방법들 중 가장 효과적이라고 느꼈던 병렬 처리에 대해서 소개하겠습니다.
제가 병렬 처리를 적용하고자 생각했던 부분은 유사 문서 탐색 부분이었습니다.
# 커뮤니티 데이터 삽입 -> 처리 시작 -> 처리 완료 -> 공지 데이터 삽입 -> 처리 시작 -> 처리 완료기존에는 위와 같은 구조로 문서 탐색을 진행하고 있었습니다.
그런데 커뮤니티 데이터와 공지 데이터 모두 search_top_k라는 함수를 사용하고 있었고,
둘다 유사 문서 탐색 단계라는 같은 단계에 속한 작업이었기에 병렬 처리 적용을 고려하게 되었습니다.
(혹시 데이터 자체를 합친다는 생각을 하셨다면, 이 부분에 대해서는 신중하게 생각하셔야 합니다. AI에게 신뢰할 수 있는 공지 데이터와 참고할 수 있는 커뮤니티 데이터를 적절하게 나누는 것은 답변 생성 품질에 큰 영향을 미치기 때문입니다. 각 데이터의 특성을 파악하시고 분리하거나 합치시기를 권장합니다.)
import asyncio
먼저 병렬 처리를 도와줄 asyncio 라이브러리를 가져와줍니다.
related_docs, related_notice_docs = await asyncio.gather(
asyncio.to_thread(search_top_k, msg, docs, embedded_vectors, 4),
asyncio.to_thread(search_top_k, msg, notice_docs, notice_vec, 7)
)그리고 위와 같이 asyncio.gather를 이용하여 2개의 문서 탐색 코드를 병렬로 처리해줍니다.
위에서 말했듯이 같은 로직으로 같은 함수를 이용하여 처리하고 있었기에 별다른 설정 없이 바로 병렬로 처리할 수 있었습니다.


병렬 처리를 적용한 이후 바로 측정을 해보았고, 약 10초 가량의 큰 시간을 개선한 것을 확인할 수 있었습니다.
간단한 답변의 경우 18초 ~ 19초 정도로 확실히 개선된 모습을 보였고, 전체 평균도 약 20초로 굉장히 긍정적인 결과가 나왔습니다.
무엇보다 저는 GPT 스트림 기능을 적용중이었기 때문에 답변 시작이 아닌, 전체 답변 생성이 20초라는 점은 실사용 서비스로도 굉장히 적합한 수치였습니다.
💡 요약
- 문서 탐색 단계를 병렬로 처리함
- 약 10초 가량의 시간을 줄일 수 있었음
- 실제 서비스로 사용할 수 있을만한 수준이 됨
😊 마무리
이렇게 오늘은 RAG 구조에서의 답변 생성 시간을 개선하기 위해 시도했던 방법들에 대해서 정리하고,
실제 측정 시간과 함께 분석까지 해보았습니다. 효과적이었던 방법도 있었고, 별로 효과적이지 않은 방법도 있었지만, 모든 과정이 새로운 것을 배우는 뜻 깊은 시간이었습니다.
여러분들도 저와 비슷한 문제를 겪고 있다면 제 글을 통해 많은 도움을 받으셨으면 좋겠습니다.
실제로 배포 가능한 프로젝트를 기획하고 개발하다 보니, 어느 순간부터 "아 다 만들었다"가 아닌 "근데 이걸 사용자가 사용할까?" 라는 관점에서 계속 보게 되는 것 같습니다.
그러다 보니 단순 기능 구현에서 멈추지 않고, 제품의 품질을 어떻게 끌어올릴 수 있을지, 실제로 사용자가 편하게 느낄 수 있을지 등을 고민하며 개발하게 되었습니다.
앞으로도 계속해서 더 좋은 성능과 기능을 갖춘 서비스를 만들기 위해 노력하겠습니다.
지금까지 읽어주셔서 감사드리고, 저와 같이 소통하고 프로젝트를 만들어보고 싶다면 아래 링크로 들어와주세요!
KYT CODING COMMUNITY Discord 서버에 가입하세요!
Discord에서 KYT CODING COMMUNITY 커뮤니티를 확인하세요. 20명과 어울리며 무료 음성 및 텍스트 채팅을 즐기세요.
discord.com
KYT CODING COMMUNITY 가입하기!